
Long Context Transfer from Language to Vision
Peiyuan Zhang*;†1;2, Kaichen Zhang*;1;2, Bo Li*;1;2, Guangtao Zeng3, Jingkang Yang1;2, Yuanhan Zhang1;2, Ziyue Wang2, Haoran Tan2, Chunyuan Li1, Ziwei Liu1;2,
1LMMs-Lab Team 2NTU, Singapore 3SUTD, Singapore
*equal contribution.
†project lead.
Table of Contents
Introduction & Results
Gemini has amazed the world with its capability to understand hour-long videos. However, we still lack an open-source alternative with similar capabilities. Our latest research introduces an innovative solution towards long video Large Multimodal Models (LMMs), shifting the focus from reducing visual tokens per frame to leveraging the long context capabilities of language models. In this blog post, we present our SoTA video model, Long Video Assistant (LongVA), and our novel benchmark, Visual Needle-In-A-Haystack (V-NIAH).
Long Context Transfer We discovered and verified that the long context capability of language models can be directly transferred to the video domain in modality-aligned multi-modal models. On V-NIAH, LongVA is capable of accurately retrieving visual information from inputs with 2000 frames or more than 200K visual tokens.
SoTA Performance LongVA achieves state-of-the-art performance on the Video-MME benchmarks among 7B models. Its performance increases with denser sampling of video frames. Notably, it is the only opensource model on Video-MME that can handle 384 input frames (same as GPT4-o).
We opensource the code and models at:


Methods
Current open source LMMs show promising performance on tasks involving single images and short videos. However, effectively processing and understanding extremely long videos remains a significant challenge. One primary difficulty is the excessive number of visual tokens generated by the vision encoder. For example, LLaVA-1.6 can produce visual tokens anywhere from 576 to 2880 for a single image. The number of visual tokens increases significantly with the addition of more frames in videos. To tackle this issue, various methods have been proposed to reduce the number of visual tokens. One popular approach is to modify the visual resampler that connects the vision encoder to the language model, aiming to extract fewer tokens. Other strategies involve heuristic techniques to prune or merge the visual features. However, despite these efforts, most current language models for multimedia still struggle to process a large number of frames effectively. At the day of writing this blog post, mojority of opensource LMMs can only handle 8 to 64 frames.
As shown in the below figure, our method shifts the focus from reducing the number of visual tokens to increasing upper bound of the visual tokens that a LMM can handle. We hypothesize that if the modality of vision and language can be truly aligned, the capability to handle long contexts could also transfer from text to vision, and this could happen even without explicit long video training. Our methodology is thus straightforward. We start with a language model and perform long context training purely on text to extend its text context capabilities. Once this is achieved, we augment the language model with visual capabilities by training it solely on short image data. If our hypothesis is true, this two-step process would ensure that the model can handle both extended text contexts and visual information effectively.

Training Long Language Model
We use Qwen2-7B-Instruct as the backbone language model and perform continued pretraining with a context length of 224K1 over a total of 900M tokens. We increase RoPE base frequency during the continued pertaining and specifically set it to 1B. A constant learning rate of 1e-5 is maintained for a batch size of one million tokens across 1,000 training steps. Following Fu et al. (2024), we construct the dataset used for long context training from Slimpajama by upsampling documents longer than 4096 and keeping the domain mixture ratio unchanged. Multiple documents are packed into a single sequence separated by a BOS token.
We employed several optimization strategies to perform training on such long sequences. These include FlashAttention-2, Ring Attention, activation checkpointing, and parameter offload. To balance the load across different GPUs, we shard the sequence in a zigzag way in ring attention. The resulting training framework is memory efficient and maintains very high GPU occupancy. Note that we do not use any parameter-efficient methods such as LoRA or approximate attention. With those optimizations, the compute used in long context training is minimal compared to that of language model pretraining, making it feasible for academic budgets. The long context training can finish in 2 days with 8 A100 GPUs.
Aligning Long Language Model Using Short Vision Data
Inspired by the AnyRes encoding scheme in LLaVA-NeXT, we designed UniRes that provides a unified encoding scheme for both images and videos, as shown below. Unlike AnyRes which retains a small base image and flattens ViT patches across the grids, UniRes removes the base image, flattens patches within each grid, and 2x2 pool the visual features by default.This approach allows us to maintain consistent representation when extending image data into videos where multiple frames are viewed as multiple grids in a row.
To clearly ablate the long context transfer phenomenon from language to vision, we adopt a train short, test long protocol where we only use image-text data during training, but test on long videos. Specifically, we trained our model using the same data recipe and two-stage training approach as LLaVA-1.6.

Example Demonstrations
We provide the following examples to demonstrate LongVA’s capabilities on real-world long and short videos, including some extremely long videos up to 30 minutes.

For more interactive demonstrations, please refer to the LongVA Demo.
V-NIAH Evaluations
To measure the context length of language models on extremely long inputs, earlier works used perplexity scores over long documents. We propose a new benchmark, V-NIAH, to evaluate the visual context length of LMMs.
In V-NIAH, we embedded five video question-answering challenges, termed needles into hours-long videos sampled at 1 FPS. These needles, sourced from existing VQA benchmarks or generated by AI to avoid biases, are designed to be counterfactual, ensuring answers rely solely on visual cues rather than language knowledge. Each needle is accompanied by a locating prompt to aid in identifying the relevant frame within the video haystack.

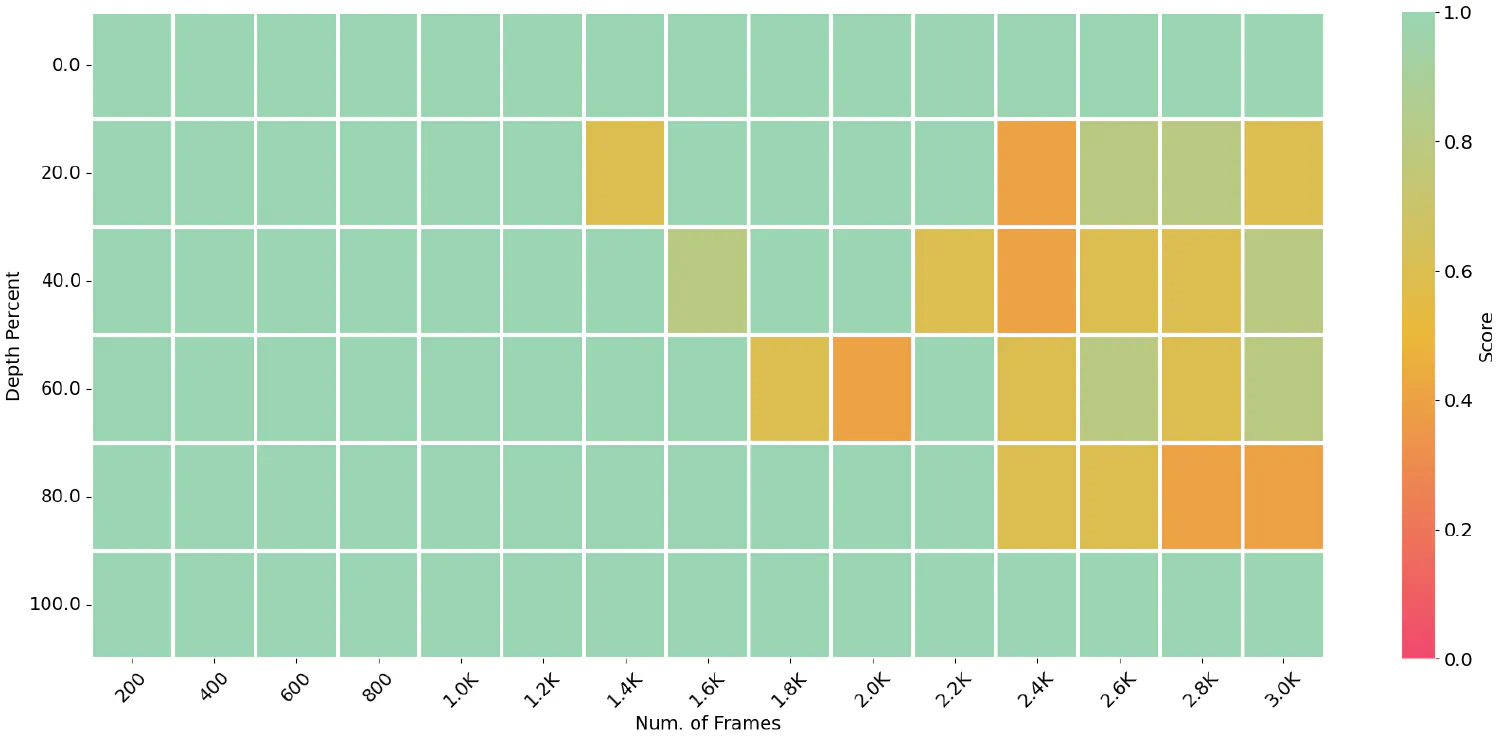
Figure 4 illustrates the performance of LongVA in the V-NIAH test, comparing it with LLaVA-NeXT-Video-32K and LongVA using the AnyRes encoding scheme. The bottom left plot shows that LLaVA-NeXT-Video-32K’s performance declines sharply once the input exceeds its language model’s training length. To address this, we experimented with training-free length extrapolation by adjusting the RoPE base frequency, testing various frequencies from 3M to 1B. Although this method extended the context length, the performance improvements were modest, as depicted in the bottom right plot. LongVA, on the other hand, can effectively retrieves information and answers questions within 2000 frames and maintains good performance up to 3000 frames, despite being trained on a context length of 224K tokens.
Conclusion
This work addresses the challenges of understanding long videos in Large Multimodal Models. By extending the language model on text and then aligning this extended model with visual inputs, we significantly improved the capability of LMMs to handle long videos thanks to the long context transfer phenomenon. Our model, LongVA, shows improved performance with more input frames and achieves state-of-the-art results on Video-MME. Additionally, we introduce a synthetic benchmark, V-NIAH, to effectively measure the visual context length of video LMMs. We hope this work inspires further research in the field of long-vision models and multimodal agents.
Related Projects
224K is the maximum we can fit with 8 A100-80G for Qwen-2-7B. We find that the embedding size significantly impacts the maximum sequence length in our optimized codebase. Qwen2 has a huge vocabulary of 152K tokens. For LLaMA2 with 32K vocabulary, we can train it with 700K context length. ↩︎