
Embracing Video Evaluations with LMMs-Eval
Kairui Hu*,
Fanyi Pu*,
Kaichen Zhang*,
Shuai Liu*,
Yuanhan Zhang*
Bo Li*;†,
Peiyuan Zhang,
Ziwei Liu
Nanyang Technical University, Singapore
*indicates equal contribution.
†development lead.
Table of Contents
Introduction
In the journey towards multimodal intelligence, the development of LMMs has progressed remarkably, transitioning from handling static images to processing complex video inputs. This evolution is crucial, enabling models to understand and interpret dynamic scenes with temporal dependencies, motion dynamics, and contextual continuity. The importance of video evaluation is also increasing across various applications. However, there has been a noticeable absence of comprehensive benchmarks to evaluate the diverse array of video tasks. The introduction of lmms-eval/v0.2.0 is both necessary and significant as it addresses this critical gap in the evaluation of video-based LMMs.
Building upon the success of lmms-eval/v0.1.0, lmms-eval/v0.2.0 makes major upgrades on incorporating video tasks and models, and more feature updates on improved pipelines for both image and video tasks, more image models, and fixed previous community issues.
Video Evaluation in LMMs
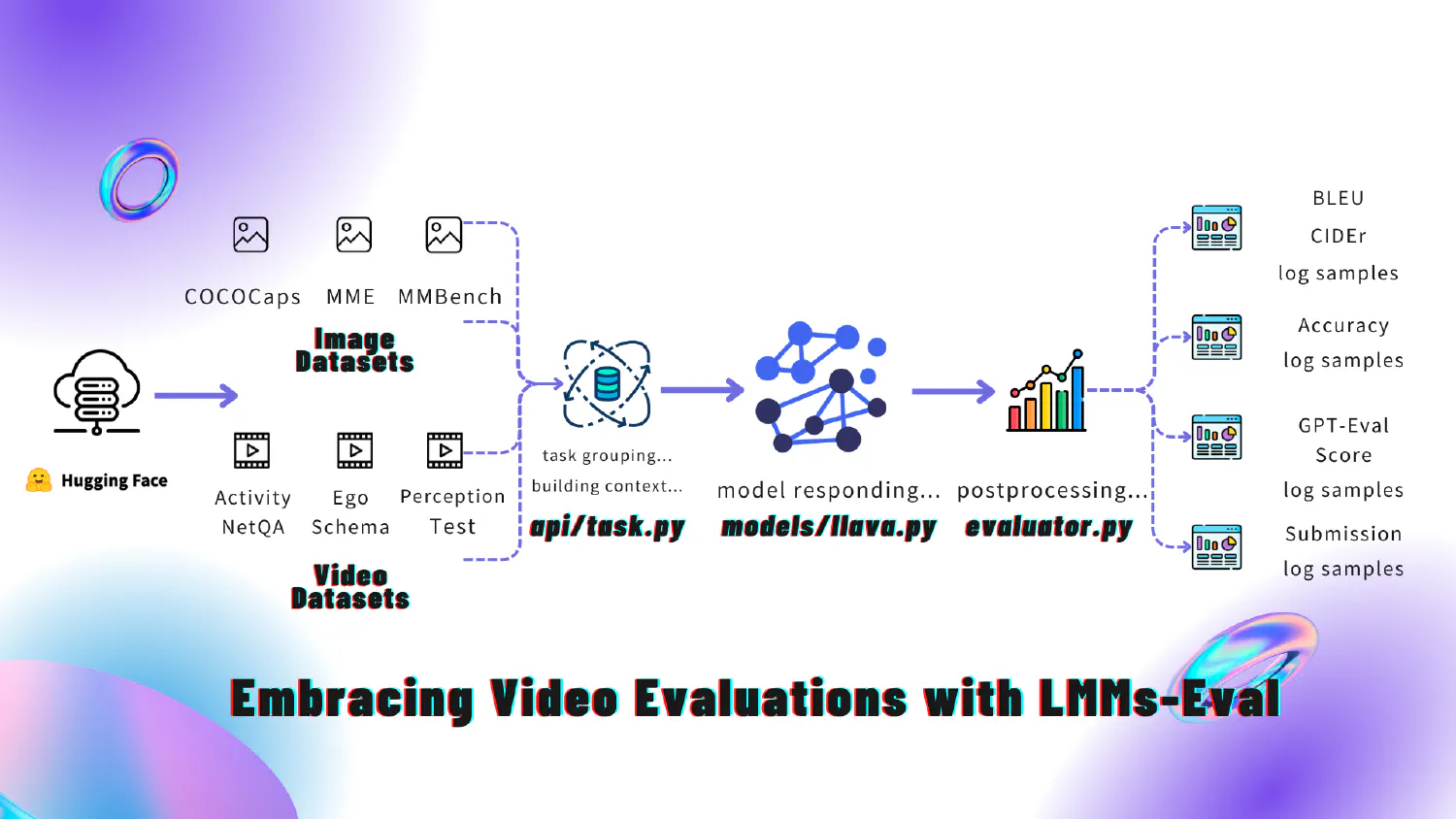
Frame Extraction for Evaluation
In our framework, video evaluation can be viewed as extracting multiple frames to represent a video and then feeding the multi-frame input to the model for inference. This perspective allows us to enhance the zero-shot video understanding capability of image models by utilizing their potential to process sequences of frames as visual tokens. When each frame is considered as part of a concatenated sequence, image-only-trained models like LLaVA-Next can achieve impressive performance on video-related tasks. This highlights the significant advancement in the zero-shot video understanding capability of image models, representing a notable step forward for LMMs.
When defining these models, we also specify the number of frames to be extracted. Extracting more frames typically enhances the model’s understanding of the entire video.
Besides, some models like Gemini and Reka do not expose the video processing interface. Our interface accommodates this by directly uploading the raw data files for evaluation.
Challenges with Audio Integration
One of the most concerning issues with these evaluations is the lack of focus on audio inputs. The majority of current evaluations overlook audio, which is a significant drawback. Audio plays a pivotal role in video content, offering supplementary context and information. At present, only the WorldQA dataset explicitly necessitates audio information to answer questions accurately. This underscores a critical gap in the evaluation process that future frameworks must address to ensure a more comprehensive evaluation of video understanding.
Meta Information for Video Datasets
Table 1: Video Dataset Meta Information
| Dataset | Split | Task Name | Task Format | Evaluation Metric | Video Source | Average Length |
|---|---|---|---|---|---|---|
| ActivityNet-QA | Test | activitynetqa | Open-ended | GPT-Eval | Internet | 117.3s |
| EgoSchema | Full | egoschema | MCQ | Submission | Ego4D | 180s |
| YouCook2 | Validation | youcook2_val | MCQ | Bleu; METEOR; ROUGE_L; CIDEr | YouTube | 311.6s |
| Vatex | Test | vatex_test | Caption Matching | Bleu; METEOR; ROUGE_L; CIDEr | YouTube | 147.6s |
| Vatex-ZH | Validation | vatex_val_zh | Caption Matching | Bleu; METEOR; ROUGE_L; CIDEr | YouTube | 165s |
| VideoChatGPT | Test | videochatgpt | Open-ended | GPT_Eval | ActivityNet-200 | 108s |
| VideoDetailCaptions | Test | video_dc499 | Open-ended | GPT_Eval | ActivityNet-200 | 108s |
| NextQA | OE (Text / Validation), MC (Test) | nextqa | MCQ / Open-ended | MC: Exact Match; OE: WUPS | YFCC-100M | 44s |
| CVRR-ES | Default | cvrr | Open-ended | GPT_Eval | Internet; Public dataset | 22.3s |
| Perception Test | MC | perceptiontest_val_mc | MCQ | Accuracy | Internet | 23s |
| TempCompass | Default | tempcompass | MCQ; Y/N; Captioning; Caption Matching | Accuracy | Internet | 11.9s |
| Video-MME | Test | videomme | MCQ | Accuracy | YouTube | 1017s |
Alignment Check for Video Datasets
Table 2. Alignment Check for Video Datasets
| Dataset | Subset | Model | Original Reported | LMMs-Eval |
|---|---|---|---|---|
| EgoSchema(0-shot) | egoschema_subset_mc_ppl | LLaVA-NeXT-Video-7B | - | 50.60% |
| CVRR-ES | cvrr_multiple_actions_in_a_single_video | Video-ChatGPT | 27.67% | 28.31% |
| CVRR-ES | cvrr | LLaVA-NeXT-Video-7B | - | 44.29% |
| TempCompass | tempcompass_caption_matching | LLaVA-1.5-13B | 59.50% | 59.35% |
| VideoChatGPT | videochatgpt_temporal | LLaVA-NeXT-Video-7B | Score: 2.60 / 5 | Score: 2.67 / 5 |
| NextQA | nextqa_oe_test | LLaVA-NeXT-Video-7B | 26.90% | 26.61% |
| VATEX | vatex_test | LLaVA-NeXT-Video-7B | - | CIDEr: 39.28 |
| ActivityNetQA | activitynetqa | LLaVA-NeXT-Video-7B | 53.5% | 52.72% |
| VideoDetailCaptions | video_dc499 | LLaVA-NeXT-Video-7B | Score: 3.32 / 5 | Score: 3.50 / 5 |
| Video-MME (wo/subs) | videomme | LLaVA-NeXT-Video-7B | - | 41.98% |
More Details and Feature Updates with v0.2.0
Improved Pipeline for Video Evaluations
Here’s a breakdown of adding video datasets support, especially on how we implement the process from video caching, loading and feed to model to get response.
Download and Load Videos: Video are being loaded during generation phase. We will host different video datasets on the huggingface and preprocess the video path for you in your huggingface cache folder. It is recommended to set
HF_HOMEbefore you use our evaluation suite so that you can manage the download place. After downloading the videos from huggingface hub, we unzip them into a local cache dir, where by default isHF_HOME.The code specifically demonstrates the logic of how we handle video datasets in lmms-eval.
@retry(stop=(stop_after_attempt(5) | stop_after_delay(60)), wait=wait_fixed(2)) def download(self, dataset_kwargs=None) -> None: # If the dataset is a video dataset, # Recursively search whether their is a zip and unzip it to the huggingface home if dataset_kwargs is not None and "video" in dataset_kwargs and dataset_kwargs["video"]: hf_home = os.getenv("HF_HOME", "~/.cache/huggingface/") cache_dir = dataset_kwargs["cache_dir"] cache_dir = os.path.join(hf_home, cache_dir) accelerator = Accelerator() if accelerator.is_main_process: cache_path = snapshot_download(repo_id=self.DATASET_PATH, repo_type="dataset") zip_files = glob(os.path.join(cache_path, "**/*.zip"), recursive=True) if not os.path.exists(cache_dir) and len(zip_files) > 0: for zip_file in zip_files: eval_logger.info(f"Unzipping {zip_file} to {cache_dir}") shutil.unpack_archive(zip_file, cache_dir) accelerator.wait_for_everyone() if "builder_script" in dataset_kwargs: builder_script = dataset_kwargs["builder_script"] self.DATASET_PATH = os.path.join(cache_path, builder_script) dataset_kwargs.pop("builder_script") dataset_kwargs.pop("cache_dir") dataset_kwargs.pop("video")
Format questions: For each task, questions are formatted in the
<taskname>/utils.pyfile. We parse each document from the Huggingface dataset, retrieve the questions, and formulate the input with any specified model-specific prompts.The code specifically demonstrates the logic of how to implement question format.
# This is the place where you format your question def perceptiontest_doc_to_text(doc, model_specific_prompt_kwargs=None): if model_specific_prompt_kwargs is None: model_specific_prompt_kwargs = {} pre_prompt = "" post_prompt = "" if "pre_prompt" in model_specific_prompt_kwargs: pre_prompt = model_specific_prompt_kwargs["pre_prompt"] if "post_prompt" in model_specific_prompt_kwargs: post_prompt = model_specific_prompt_kwargs["post_prompt"] question = doc["question"] if "options" in doc: index = 0 for op in doc["options"]: if index == 0: question += "\n" + "A. " + op elif index == 1: question += "\n" + "B. " + op else: question += "\n" + "C. " + op index += 1 post_prompt = "\nAnswer with the option's letter from the given choices directly." print("question\n") print(question) return f"{pre_prompt}{question}{post_prompt}"
Process results: After the model generates results, each result is parsed and evaluated based on the corresponding evaluation metric. The choice of metric is based on the dataset’s official implementation on their official project website. We primarily use three types of metrics:
a. Accuracy: For datasets with ground truth answers, we generate a score by comparing the model’s results with the ground truth. This metric is commonly used in multiple-choice QA tasks such as PerceptionTest-val and EgoSchema-subset.
b. GPT Evaluation: For open-ended answers generated by the model, we apply OpenAI GPT API to evaluate the responses. This metric is often used in generation tasks like ActivityNetQA and VideoChatGPT.
c. Submission: If the dataset does not provide ground truth answers and requires submission of inference results to a server for evaluation, we provide a submission file according to the dataset’s official template. This metric is used in tasks like EgoSchema, Perception Test.
Aggregate results: After evaluating each data instance, we aggregate the individual results to generate the overall evaluation metrics. Finally, we provide a summary table that consolidates all the evaluation results, similar to the one in Google’s Gemini report.
Grouped Tasks: For tasks with multiple subsets, we group all subset tasks together. For example, the VideoChatGPT dataset includes three subsets: generic, temporal, and consistency. By running
--task videochatgpt, all three subsets can be evaluated together, eliminating the need to specify each subset individually. We summarize all the grouped task names in Table 1. This pipeline ensures a thorough and standardized evaluation process for video LMMs, facilitating consistent and reliable performance assessment across various tasks and datasets. - This code denotes how we organize the group of tasks together.group: videochatgpt task: - videochatgpt_gen - videochatgpt_temporal - videochatgpt_consistency
Improved Overall Evaluation Pipeline
For newly added tasks with different splits and metrics, we have adopted a naming rule in the format
{name}_{split}_{metric}. For instance,perceptiontest_val_mcpplrefers to the validation split of the PerceptionTest evaluation dataset, using multiple choice perplexity as the evaluation metric.We support
llava-nextseries models with sglang. You can use the following command to launch evaluation with sglang support, that’s much more efficient when running onllava-next-72b/110bpython3 -m lmms_eval \ --model=llava_sglang \ --model_args=pretrained=lmms-lab/llava-next-72b,tokenizer=lmms-lab/llavanext-qwen-tokenizer,conv_template=chatml-llava,tp_size=8,parallel=8 \ --tasks=mme \ --batch_size=1 \ --log_samples \ --log_samples_suffix=llava_qwen \ --output_path=./logs/ \ --verbosity=INFOWe add a
force_downloadmode to robustly handle the case that videos are not fully cached in local folder. You could add the args to task yaml file as the following commands. To support the evaluations that in machines that do not have access to internet, we add thelocal_files_onlyto support this feature.dataset_path: lmms-lab/ActivityNetQA dataset_kwargs: token: True video: True force_download: False local_files_only: False cache_dir: activitynetqa model_specific_prompt_kwargs: default: pre_prompt: "" post_prompt: " Answer the question using a single word or phrase." metadata: version: 0.0 gpt_eval_model_name: gpt-3.5-turbo-0613We found that sometimes the dataset downloading process will throw
RetryorHTTP Timedouterrors. To prevent this, we recommend disablinghf_transfermechanism by setting this in your environmentexport HF_HUB_ENABLE_HF_TRANSFER="0"mmmu_group_img_val
We aligned the results of LLaVA-NeXT 34B with previously reported values. In our previous evaluation, for the questions with multiple images, we concatenated them into one. When tested separately (
mmmu_val), the score was 46.7, and after we do the concatenation operation (in lmms-eval, you could switch to usetasks=mmmu_group_img_val), the score was 50.1 for LLaVA-NeXT 34B.Example Images and QA Pairs

A collimated beam containing two different frequencies of light travels through vacuum and is incident on a piece of glass. Which of the schematics below depicts the phenomenon of dispersion within the glass in a qualitative correct manner? Select (e) if none of the options are qualitatively correct. (A) <image 1> (B) <image 2> (C) <image 3> (D) <image 4> Answer with the option's letter from the given choices directly.Predict Only Mode - Only Inference, No Evaluation
In some cases, you may want to obtain only the inference results, without triggering the evaluation process. For this purpose, we have integrate the
predict_onlymode from the originallmms-eval. This feature allows you to obtain model inference results without performing further evaluation. It is particularly useful when you do not need to evaluate your model results, for instance, if the dataset requires ChatGPT-based evaluation but you do not want to use the OpenAI API.To use the
predict_onlymode, add the--predict_onlyflag to your command. This will override the original evaluation process with a bypass function after obtaining the model inference results and simply save the results as logs.From-Logs Mode - Evaluation Based on Log Files from
predict_onlymodeaccelerate launch -m lmms_eval \ --model=from_log \ --tasks=<taskname> \ --batch_size=1 \ --log_samples \ --output_path=./logs/ \ --model_args=logs=<path_to_log_directory>,model_name=<model_name>,model_args \ --verbosity=DEBUGIn some cases, you may want to evaluate model performance using pre-existing inference results. For this purpose, we have designed the
from_logmode. This feature allows you to evaluate model performance directly from inference results recorded in thelogs/directory. This mode saves time and enhances portability, consistency, and reproducibility. It is particularly useful when you already have model inference results and wish to avoid running the inference process again.Currently, we only support inference results stored in the
logs/directory, which is the log file generated from our pipeline. Hence currently, the file template of these results is pre-defined. If you need to evaluate the inference result generated by yourself, you may have to convert your file into the same template as those underlogs/.To use the
from_logmode for performance evaluation based on existing log files, you can run the following command. You can specify thetask_name,path_to_log_directory,model_nameandmodel_args(if specified). Our framework will traverse through all the log files within the specified directory and find the most recent log file for evaluation.Combined Use of Two Modes
You can use the two modes together: using the
predict_onlymode to obtain model inference results, and using thefrom_logmode to evaluate the generated inference results. This enhances the overall consistency and reproducibility of our framework.You can use the following command to run the two modes together:
# Open predict_only mode to inference accelerate launch --num_processes 8 --main_process_port 12345 -m lmms_eval \ --model <model_name> \ --tasks $TASK \ --batch_size 1 \ --log_samples \ --log_samples_suffix <model_name> \ --output_path ./logs/ \ --predict_only # Open from_log mode to evaluate accelerate launch --num_processes 8 --main_process_port 12345 -m lmms_eval \ --model from_log \ --model_args model_name=<model_name>\ --tasks $TASKS \ --batch_size 1 \ --log_samples \ --log_samples_suffix <model_name> \ --output_path ./logs/
Newly Supported Video Tasks
- ActivityNet-QA
- EgoSchema
- YouCook2
- VATEX
- VATEX-ZH
- VideoChatGPT
- VideoDetailCaptions
- NextQA
- CVRR-ES
- Perception Test
- TempCompass
- Video-MME
Newly Supported Video Models
We have supported more video models that can be used in LMMs-Eval. We now support evaluating video datasets using a one line command.
Community Support
During this period, we received the following Pull Requests (PRs):
Details are in lmms-eval/v0.2.0 release notes
Datasets:
- VCR: Vision Caption Restoration (officially from the authors, MILA)
- ConBench (officially from the authors, PKU/Bytedance)
- MathVerse (officially from the authors, CUHK)
- MM-UPD (officially from the authors, University of Tokyo)
- WebSRC (from Hunter Heiden)
- ScreeSpot (from Hunter Heiden)
- RealworldQA (from Fanyi Pu, NTU)
- Multi-lingual LLaVA-W (from Gagan Bhatia, UBC)
Models:
- LLaVA-HF (officially from Huggingface)
- Idefics-2 (from the lmms-lab team)
- microsoft/Phi-3-Vision (officially from the authors, Microsoft)
- LLaVA-SGlang (from the lmms-lab team)