
Blog
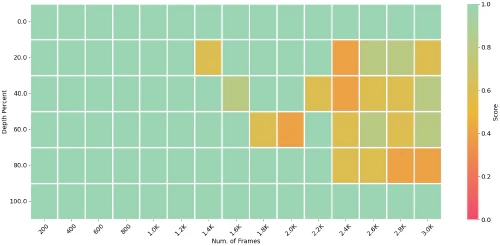
Long Context Transfer from Language to Vision
Our paper explores the long context transfer phenomenon and validates this property on both image and video benchmarks. We propose the Long Video Assistant (LongVA) model, which can process up to 2000 frames or over 2000K visual tokens without additional complexities.
Tags:
Video Models
6
min read
Embracing Video Evaluations with LMMs-Eval
We introduce a video evaluation feature to lmms-eval, supporting video model evaluations with over most popular datasets.
Tags:
Video Models
10
min read

Accelerating the Development of Large Multimodal Models with LMMs-Eval
One command evaluation API for fast and thorough evaluation of LMMs, providing multi-faceted insights on model performance with over 40 datasets.
Tags:
Lmms-Eval
5
min read